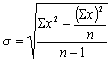Анализ количественных признаков
Важнейшим
статистическим параметром можно считать
среднюю величину. Будучи чисто
математической функцией, средняя
арифметическая, тем не менее, обладает
вполне конкретным и почти интуитивно
понятным содержанием. Неслучайно её
используют в самых разнообразных отраслях
человеческой деятельности, иногда даже
имея смутное представление о
математической статистике и её законах.
Полученная средняя величина, в первую
очередь, отражает наиболее типичные
значения признака, что позволяет
рассматривать её как параметр, на основании
которого можно судить не только о свойствах
отдельной выборки, но и о генеральной
совокупности. В общем виде, среднее
значение есть величина, вокруг которой
концентрируются все прочие варианты
совокупности. Различают несколько типов
средних (средняя квадратическая, средняя
кубическая, средняя геометрическая), однако
практически чаще используют среднюю
арифметическую величину. Она представляет
собой отношение суммы значений вариантов к
числу наблюдений.
Математически
это можно выразить следующей формулой:
![]() ,
(3.1.)
,
(3.1.)
где
Мx – среднее
арифметическое признака x
(от англ. mean –
среднее), n – число
наблюдений, S -
суммирование значений вариантов (x).
При
многочисленных выборках, когда по исходным
данным построены вариационные ряды,
формула для вычисления средней
арифметической приобретает вид:
![]() ,
(3.2.)
,
(3.2.)
где
f – частота вариант
по отдельным классам.
В
качестве примера рассчитаем по формуле (3.2.)
среднее число глазков на 40 клубнях
картофеля (см. вариационные
ряды)
![]() .
.
Средняя
арифметическая обладает рядом свойств,
часть из которых позволяет существенно
упростить её вычисление. Так, если все
варианты выборки уменьшить (увеличить) на
одно и то же число, то средняя
арифметическая соответственно уменьшится (увеличится)
на то же число. Это свойство позволяет
вычислять среднюю арифметическую не по
исходным значениям вариантов, а по
уменьшенным (увеличенным) на одно и то же
число. Вернёмся к выше рассмотренному
вариационному ряду длины предплечья 53
особей большого трубконоса (см.
вариационные ряды). Обозначим условную
среднюю величину как M'.
Уменьшим значение вариант на 36.0 мм,
получаем:
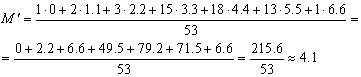 .
.
Отсюда
средняя длина предплечья большого
трубконоса, судя по данной выборке, равна М
= 4.1+36 = 40.1 мм.
Средняя
величина, как и всякий статистический
параметр, характеризует лишь одно из
свойств анализируемого явления и
игнорирует другие, в частности, она не
отражает такое важнейшее свойство, как
изменчивость. В качестве модели
изменчивости признака нередко применяется
простейший показатель, основанный на
крайних (минимальном min и максимальном max)
значениях, получивших название лимитов
(limit). В биологии
лимиты относительно
широко используются в определительных
таблицах с целью упрощения идентификации
видов (подвидов). Кроме того, иногда
рассчитывают разность между крайними
значениями вариант: xmax
- xmin или
отношение этих величин друг к другу: xmax /
xmin.
Существенный
недостаток подобных показателей - это их
зависимость исключительно от крайних,
наименее типичных значений и полное
игнорирование прочих вариантов. Для
иллюстрации этого рассмотрим два
простейших вариационных ряда:
| Ряд 1 | Ряд 2 | ||||||||||
| x1 | 1 | 2 | 3 | 4 | 5 | x2 | 1 | 2 | 3 | 4 | 5 |
| fx1 | 1 | 2 | 8 | 2 | 1 | fx2 | 1 | 4 | 4 | 4 | 1 |
Нетрудно
заметить, что оба ряда полностью совпадают
по средней величине, числу наблюдений и
лимитам (M = 3; n = 14; xmin=1;
xmax=5), и тем не менее первый
вариационный ряд явно отличается меньшим
разбросом.
В
связи с этим для оценки изменчивости
признаков предложен ряд параметров, у
которых точкой отсчёта для измерения
рассеяния отдельных вариантов служит
средняя величина. Из таких параметров в
практической работе наиболее широко
применяется среднее квадратическое или стандартное
отклонение (термин введен Пирсоном в
1894 году), представляющее собой следующее
соотношение:
Из
этой формулы видно, что при вычислении
стандартного отклонения учитывается
разница между отдельным вариантом серии
наблюдений и их средней величиной: (x
- Mx). При этом
каждое отклонение возводится в квадрат для
того, чтобы нивелировать равновесие
отрицательных и положительных отклонений
вариантов от средней, так как S(x - Mx) = 0.
Математическое обоснование формулы
приводится в [Баврин, 2002].
Считается,
что вычисление стандартного отклонения
прямым путём довольно трудоёмко, так как
для этого необходимо из каждого значения x
вычитать среднюю величину Mx,
возводить все полученные разности в
квадрат, а затем суммировать их [Бейли,
1962].
Поэтому иногда вместо этого удобнее
использовать формулу:
В
случае если по данным наблюдений построен
вариационный ряд формулы (3.3.) и (3.4.)
приобретают вид соответственно:
![]() (3.5.),
(3.5.),
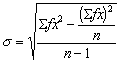 (3.6.).
(3.6.).
Стандартное
отклонение очень удобная и понятная
характеристика, которая выражается в тех же
единицах измерения, что и анализируемый
признак. Одно из важнейших его свойств
заключается в том, что, зная среднюю
величину и стандартное отклонение в
отдельной выборке, можно с определённой
уверенностью судить о генеральной
совокупности, из которой взята эта выборка.
Из теории статистики и эмпирических
исследований известно, что выборка,
репрезентативно отражающая генеральную
совокупность, как правило, обладает
следующими свойствами:
ü
в пределах M
± 1s
сконцентрировано 68.3 % вариантов
генеральной совокупности;
ü
в пределах M
± 2s
сгруппировано 95.5 % вариантов
генеральной совокупности;
ü
в пределах M
± 3s
расположено 99.7 % вариантов генеральной
совокупности.
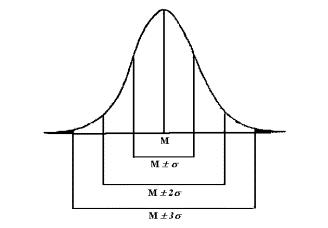
Рис.
4. Диаграмма
нормального распределения.
Указанная
закономерность, получившая название нормального
распределения, является одной из
ключевых в вариационной статистике и её
следует запомнить. Термин “нормальное
распределение” введен в биологическую
лексику Гальтоном в 1889 году. Однако ещё
задолго до этого оно было хорошо известно
математикам, которые это распределение
часто называют законом Гаусса – Лапласа.
Как видно из рисунка 4, нормальное
распределение или распределение Гаусса -
Лапласа графически может быть отображено
симметричной колоколообразной кривой,
вершиной которой является свойственная
генеральной совокупности средняя величина.
Возможность вероятностной оценки
генеральной средней будет рассмотрена ниже.
Подчинённость
самых различных объектов нормальному
распределению требует хотя бы
поверхностного осмысления, так как
принятие этого закона “на слово” может
завести нас в область метафизики.
Рассмотрим вначале пример, не относящийся к
области биологии. Представим рабочего,
изготавливающего детали определенного
размера. Логично предположить, что большая
часть из произведённых им деталей будет
совпадать или незначительно отклоняться от
требуемой величины. Однако, каков бы ни был
навык у данного рабочего, он человек и ему
свойственно делать ошибки. При этом, чем
больше отклонение от необходимого размера
детали, тем ниже вероятность того, что
рабочий произведёт такую деталь. Само собой
разумеется, у другого рабочего (предположим
менее опытного) вариабельность
произведённых деталей будет отличаться,
однако общий принцип при этом останется
неизменным.
Чем
же обусловлена подчиненность многих
количественных признаков такому
распределению у животных и растений?
Известно,
что количественные признаки, в отличие от
большинства качественных, контролируются
множеством генов, часть из которых
оказывает взаимно противоположное,
компенсирующее действие. В результате
фенотип по таким признакам, в общем,
стремится к некоторому уравновешенному,
характерному для большинства особей,
среднему состоянию. Однако, так как
соотношение аллелей в локусах зависит от
чисто случайных, стохастических процессов,
практически в каждой популяции существует
вся гамма переходов от относительно малой,
до относительно большой величины того или
иного количественного признака.
Определённое воздействие на организм
оказывает и внешняя среда.
Распределение
вариантов в конкретной выборке далеко не
всегда полностью совпадает с нормальным.
Наиболее типичными несоответствиями
являются: асимметрия, то есть смещение
вершины распределения относительно
среднего значения, и эксцесс - выраженная
плоско- или островершинность распределения
[Лакин, 1990 и др.]. Однако в
большинстве случаев всё же можно
использовать тесты, основанные на
предположении о нормальности
распределения. Дело в том, что при
возрастании объёма выборки форма
выборочного распределения средней
арифметической приближается к нормальной,
даже если распределение исследуемых
переменных не является таковым [Электронный
…, 1999 и др.]. Отсюда следует, что для
статистического анализа всегда
предпочтительнее иметь многочисленную
выборку (n>30).
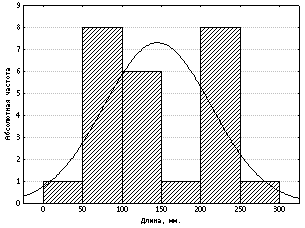
Рис.
5. Распределение длин тела (с
хвостом) 25 особей серебристого карася
Несоответствие
нормальному распределению может быть
вызвано не только спецификой варьирования
признака, но и качественной
неоднородностью выборки. Типичный пример
такого рода представлен на рисунке 5, где
проиллюстрирована изменчивость длины тела
с хвостом 25 особей серебристого карася,
отловленных в 1985 году на Манжерокском озере
(Северный Алтай). На гистограмме хорошо
видно, что форма распределения имеет
двухвершинный облик. Левая вершина
распределения соответствует возрастным
категориям: от сеголеток до двухгодовалых,
а правая – трёхлетним особям. Таким образом,
несовпадение с нормальным распределением,
в данном случае, явно обусловлено
возрастной изменчивостью анализируемого
материала. В этом и подобных случаях
первоначальную выборку целесообразнее
разбить на качественно более однородные
группы.
Практическое
применение стандартного отклонения
разберём на примере сведений о массе тела
самцов алтайской мышовки Sicista
napaea Hollister в условиях среднегорья
Северного Алтая. Полученные материалы
собраны в разные годы, но в один и тот же
сезонный период, студентами Г-АГУ, при
прохождении летних полевых практик по
зоологии позвоночных. Результаты
взвешиваний, с точностью до 0.1 гр.,
оказались следующими: 11.0, 9.3, 11.8, 9.8, 9.4, 9.4, 16.0,
9.3, 9.1, 10.8, 10.8, 8.6, 10.4, 12.0, 15.5, 9.7, 8.6, 8.7, 8.1, 10.7, 9.2, 8.3,
9.1, 7.7. Имеющаяся выборка невелика по объёму (n = 24)
и на её основании некорректно судить о
сезонной изменчивости массы тела. Поэтому,
не вдаваясь в детали, попытаемся получить
лишь общее представление об изменчивости
этого признака в пределах интересующей нас
территории. Для вычисления стандартного
отклонения воспользуемся формулой (3.4.), в
которой фигурируют такие выражения как: Sx2
и (Sx)2.
Несмотря на сходство в их написании эти
величины различны по своей сути, первая -
представляет собой сумму квадратов
значений вариантов, вторая - квадрат суммы
значений вариантов. Соответственно:
Sx2
= 11.02 + 9.32 + 11.82 + 9.82 + 9.42
+ 9.42 + 16.02 + 9.32 + 9.12 + 10.82
+ 10.82 + 8.62 + 10.42 + 12.02 +
15.52 + 9.72 + 8.62 + 8.72 + 8.12
+ 10.72 + 9.22 + 8.32 + 9.12 + 7.72
= 121 + 86.49 + 139.24 + 96.04 + 88.36 + 88.36 +256 + 86.49 + 82.81 + 116.64 +
116.64 + 73.96 + 108.16 + 144 + 240.25 + 94.09 + 73.96 + 75.69 + 65.61 + 114.49
+ 84.64 + 68.89 + 82.81 + 59.29 = 2563.91;
(Sx)2
= (11.0 + 9.3 + 11.8 + 9.8 + 9.4 + 9.4 + 16.0 + 9.3 + 9.1 + 10.8 + 10.8 + 8.6 +
10.4 + 12.0 + 15.5 + 9.7 + 8.6 + 8.7 + 8.1 + 10.7 + 9.2 + 8.3 + 9.1 + 7.7)2
= 243.32 = 59194.89.
Подставляя
вычисленные значения в формулу (3.4.)
получаем:
s
=
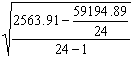 =
=
![]() =
=
![]() =
=
![]() » 2.1
гр.
» 2.1
гр.
После
нахождения средней массы тела прямым и
очевидным способом (формула 3.1.) -
M=10.1 гр.
можно, с определённой долей вероятности,
приступить к выяснению свойств генеральной
совокупности, то есть, в нашем случае, к
изменчивости массы тела самцов алтайской
мышовки, обитающих в среднегорном поясе
Северного Алтая. Принимая во внимание, что
варьирование массы тела в этом случае
приближается к нормальному, можно
утверждать, что в данных природных условиях
около 95 % самцов данного вида имеют массу
тела от 5.9 до 14.3 гр.,
или, иначе говоря, лишь 1 из 20 самцов
теоретически может выйти за пределы
указанных величин.
Стандартное
отклонение обладает рядом математических
свойств, часть из которых позволяет
упростить его вычисление. Например, если
уменьшить (увеличить) все варианты
анализируемой выборки на одно и то же число,
то стандартное отклонение не изменится. Для
иллюстрации этого обратимся к
вариационному ряду длины предплечья 53
особей большого трубконоса (см. вариационные
ряды). Как и в случае с вычислением
средней величины, уменьшим центры
классовых интервалов на 36.0 мм.
Полученные значения принимаем за условные
центры классовых интервалов x'.
Вычисляем сумму квадратов отклонений
условных центров классовых интервалов от
условной средней величины (Mx ' = 4.1
мм), как это показано
в таблице 4.
Таблица 4
| x' | f | (x' – Mx' ) | (x' - Mx' )2 | f (x' - Mx' )2 |
| 0 | 1 | -4.1 |
16.81 |
16.81 |
| 1.1 | 2 | -3.0 |
9.00 |
18.00 |
| 2.2 | 3 | -1.9 |
3.61 |
10.83 |
| 3.3 | 15 | -0.8 |
0.64 |
9.60 |
| 4.4 | 18 | 0.3 | 0.09 | 1.62 |
| 5.5 | 13 | 1.4 |
1.96 |
25.48 |
| 6.6 | 1 | 2.5 |
6.25 |
6.25 |
| Сумма: |
88.59 |
|||
Отсюда
(см. формулу (3.3.)) s =
![]() =
=
![]() = 1.3 мм.
= 1.3 мм.
Рассчитанная
таким способом величина стандартного
отклонения предметно интерпретируется так
же, как и в примере с массой тела самцов
алтайской мышовки.
Практическое
применение s
в биологических науках не ограничивается
лишь сферой морфологических и
анатомических исследований. Этот
показатель хорошо зарекомендовал себя при
упорядочивании представлений о сезонных
явлениях в природе [Фенологические
…, 1982], о распределении и динамике
численности организмов, а также при решении
вопросов селекции и генетики.
Таким
образом, стандартное отклонение
представляет собой одну из наиболее
обоснованных и эффективных описательных
статистик. Однако, если необходимо
сопоставить изменчивость признаков,
представленных в разных единицах измерения
(например, мм. и гр.)
этот показатель использовать нельзя, так
как он измеряется в тех же величинах, что и
средняя величина. Кроме того, одно и то же
значение стандартного отклонения (например,
s
= 2) может указывать как на очень малую (М
= 100), так и на очень большую изменчивость (М=5).
Для сравнения изменчивости признаков в
таких случаях лучше применять коэффициент вариации, равный
процентному отношению стандартного
отклонения к средней арифметической
величине, то есть:
![]() .
(3.7.)
.
(3.7.)
Специальными
исследованиями установлено, что
изменчивость одного и того же признака,
выраженная коэффициентом вариации, может
отличаться как у различных видов, так и у
разных популяций в пределах одного вида,
причём эти отличия зачастую не случайны и
имеют направленный характер. Это послужило
основой для формирования единых
методологических позиций при изучении
индивидуальной и эволюционной
изменчивости организмов [Яблоков,
1966; Смирнов, 1971 и др.]. Интересные
результаты, в этом плане, получены, например,
Л. Н. Добринским [1981],
который на основе анализа большого
материала по изменчивости
морфофизиологических признаков птиц
показал, что у некоторых видов степень
вариабельности интерьерных признаков
четко отличается у северных и южных
популяций, тогда как изменчивость индексов
ряда внутренних органов не совпадает с
географическими градиентами. Последнее
объясняется функциональным значением
внутренних органов (например, в любой
географической зоне требуется строго
определённое соотношение массы тела и
массы летательной мускулатуры у всех
слагающих популяцию особей).
Коэффициент
вариации находит применение и в
селекционной работе [Федоров,
1957; Снедекор, 1961 и др.]. Например, при
сравнении двух сходных по продуктивности и
качественным показателям сортов,
предпочтение должно быть отдано тому из них,
который при равных условиях обладает
меньшей изменчивостью.
Из
предыдущих разделов должно быть ясно, что
параметры M и s
вычисляются исключительно на основе
исходной серии наблюдений и их точность
зависит от того, насколько полно
анализируемая выборка представляет
генеральную совокупность. Предположим, что
при сборе первичного материала выбрана
вполне адекватная методика, чётко выдержан
принцип репрезентативности, а также не
допущено ошибок в математических
вычислениях. Будут ли полученные
статистические оценки совпадать с
истинными, свойственными генеральной
совокупности? Вообще говоря, если мы не
знаем этих "истинных" значений, то с
полной уверенностью на поставленный вопрос
нельзя ответить утвердительно. Для того,
чтобы убедиться в этом, достаточно взять из
любой природной популяции несколько
выборок, проанализировать их и сопоставить
результаты между собой. В большинстве
случаев полученные оценки будут различны.
Совершенно
очевидно, что наилучшим методом для
повышения точности оценок генеральной
совокупности по данным выборки является
увеличение объёма наблюдений. Иными
словами, ошибка статистического параметра,
вычисленного по данным выборки, будет тем
меньше, чем больше число наблюдений,
составляющих эту выборку. Такое свойство
выборочных статистик позволило
разработать ряд показателей, позволяющих
оценивать вероятные пределы, в которых
может находиться значение
соответствующего генерального параметра. В
частности, для вычисления статистической
ошибки выборочной средней M
используется следующая формула:
![]() ,
(3.9.)
,
(3.9.)
где
m - ошибка средней
величины. Остальные обозначения понятны из
предыдущих разделов.
Ошибка
средней (точнее стандартная ошибка) в
случае нормального распределения
подчиняется той же закономерности, что и
стандартное отклонение. Отличие состоит в
том, что стандартное отклонение отражает разброс всех
вариантов относительно средней, а
стандартная ошибка показывает пределы, в
которых, с известной вероятностью, может
располагаться средняя величина. Отсюда, в
интервале M ±
1m средняя величина
генеральной совокупности может находиться
с вероятностью 68.3 %, в интервале M ± 2m
- с вероятностью 95.5 %, а в пределах M
± 3m
- с вероятностью 99.7 %.
Процедуру
вычисления стандартной ошибки выборочной
средней рассмотрим на примере сведений о
длине тела самцов полёвок-экономок Microtus
oeconomus Pall., обитающих в среднегорьях
Северного Алтая. Предварительные
вычисления, идентичные вычислениям по
массе тела алтайских мышовок, показали, что
при n = 34 длина тела
характеризуется: M = 101.6
мм, s
= 15.0 мм.
Подставляем
известные значения в формулу (3.9.):
![]() .
.
В
результате проведённых вычислений мы,
конечно, не узнали "истинное" значение
средней длины тела у самцов
рассматриваемой популяции, однако теперь с
95 % вероятностью можно утверждать, что оно
находится в пределах 101.6
±
2×2.57
мм, то есть от 96.5 до
106.7 мм.
Вычисленные
таким способом доверительные интервалы
будут эффективно отражать анализируемое
явление, когда распределение исходных
вариантов соответствует нормальному.
Однако, если серия наблюдений не велика по
объёму (n£30),
то естественно ожидать, что в ней не будут
представлены те варианты, которые сильно
отклоняются от среднего значения. В
результате, это может приводить к неверной
оценке.
Метод
нахождения доверительных интервалов в
случае анализа небольших выборок найден
английским химиком и статистиком Госсетом.
Им же разработана специальная таблица, так
называемых, значений t (см.
Приложения
табл. 1). Величина t
показывает, во сколько раз необходимо
увеличить стандартную ошибку выборочного
статистического параметра для того, что бы
при определенном уровне вероятности судить
о тех пределах, в которых располагается
генеральное значение.
Использование
этой таблицы не требует особых вычислений,
поскольку величина t напрямую
зависит лишь от уровня вероятности P
и числа степеней свободы n.
В большинстве биологических исследований принимают P=0.95
(то есть 95 случаев из 100), в наиболее
ответственных случаях - 0.99 или 0.999. Число
степеней свободы n,
при нахождении доверительных интервалов
для M,
равно: n =
n - 1.
Рассмотрим
пример. Длина тела самок полёвок-экономок
из среднегорий Северного Алтая
характеризуется следующими выборочными
показателями: n = 10, M = 105.7
мм, s
= 16.7 мм.
Вычислим стандартную ошибку выборочной
средней величины:
![]() .
.
Как
в научно-исследовательских работах, так и
при решении ряда практических задач анализ
отдельных выборок редко является конечной
целью. Очень часто приходится сравнивать
эти выборки между собою и тогда закономерно
встает вопрос, - достоверны ли наблюдаемые
отличия между выборками или они
обусловлены лишь какими-то случайными
причинами (например, недостатком данных)? В
том случае, когда сравниваемые
вариационные ряды обособлены друг от друга
настолько, что наименьшее значение
признака в одной из выборок превосходит
наибольшее значение того же признака в
другой выборке можно без специального
анализа принять, что они существенно
различны. Однако необходимость сравнения
полностью изолированных вариационных
рядов редко встречается на практике. Чаще
всего сопоставляемые выборки, по значению
своих максимальных и минимальных вариант, в
той или иной мере заходят друг за друга.
Такое захождение носит название “трансгрессия”. Степень трансгрессии
может быть различной: от частичного до
полного поглощения одного вариационного
ряда другим.
Вопрос
о достоверности отличия двух сравниваемых
выборок обычно решается при помощи
сравнения их средних величин. При этом
исходят из простого правила, которое
заключается в том, что две выборки, вероятно, различны, если
разница между их средними величинами (M1
– M2) более чем в два раза
превосходит сумму их средних ошибок (m1 + m2), и почти наверняка
различны, если она превышает сумму средних
ошибок более чем в три раза.
Значительно
надежнее пользоваться при этом критерием
достоверности различий (t-критерий),
определяемым по формуле:
![]() .
(3.10.)
.
(3.10.)
Прямые
скобки здесь и далее в тексте показывают,
что результат вычисления берётся по модулю,
то есть без учёта знака.
После
вычисления фактической (эмпирической)
величины t
обращаются к таблице стандартных значений tst
(см. Приложения табл. 1). Число степеней свободы
в данном случае равно n1
+ n2 - 2. Гипотезу об отсутствии
различий между выборочными средними
отвергают, если фактически установленная
величина t
превзойдет или окажется равной
критическому (табличному) значению tst
этой величины для принятого уровня
вероятности.
Когда
число наблюдений в двух сериях различается
очень сильно, рекомендуется пользоваться
более сложной формулой:
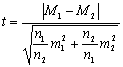 .
(3.11.)
.
(3.11.)
Однако,
по мнению Хэббса и Перлмуттера [Hubbs
et al., 1942], а вслед за ними Эрнста Майра с
соавторами [1956], формула (3.10.)
редко приводит к серьёзным ошибкам, поэтому
для большинства биологических
исследований её вполне достаточно.
Проверим,
достоверна ли разница средней величины
длины тела низкогорных и высокогорных
живородящих ящериц Lacerta vivipara Jacq. в условиях восточной
окраины Алтая. По данным В. А. Яковлева [2002]
первые характеризуются средней длиной тела
равной 54.9 ±
0.82 мм (n = 71 экз.),
вторые – 60.0 ±
0.12 мм (n = 69 экз.).
Находим
фактическую величину t:
![]() .
.
Так
как число степеней свободы n
= (71+69) – 2 = 138, стандартная величина tst (3.29
и меньше) уступает вычисленной даже при
самом высоком уровне P. Следовательно отличия
высокогорных и низкогорных особей
живородящей ящерицы L.
vivipara в высшей степени достоверны.
Оценка разности коэффициентов вариации
Сопоставление
коэффициентов вариации, с одной стороны,
позволяет оценить разность в вариации двух
различных признаков в одной выборке (популяции),
с другой – оценить разность в
вариабельности одного и того же признака в
двух выборках (популяциях). Есть мнение, что
корректной формальной основой для
этого может служить t-критерий
[Лакин, 1990].
Величину
стандартной ошибки коэффициента вариации,
в первом приближении, вычисляют по формуле [Рокицкий,
1973; Терентьев, Ростова, 1977; Лакин, 1990]:
![]() .
(3.12.)
.
(3.12.)
Фактическая
величина t определяется отношением:
![]() .
(3.13.)
.
(3.13.)
Рассмотрим
конкретный пример. На одном из озер в
окрестностях г. Горно-Алтайска отловили
несколько экземпляров серебристого карася Carassius
auratus L. В ходе изучения материала
подсчитано: число чешуй вдоль боковой линии
(n = 25) и число жаберных тычинок (n = 19). Распределение вариант по обоим
признакам приближается к нормальному.
Первый признак характеризуется
статистиками: M1 = 30.8 и s1
= 1.3, второй признак – M2
= 43.7 и s2
= 2.3. Отсюда, согласно формуле (3.7.), Cv1 = (1.3/30.8)
´
100 % = 4.22 % и Cv2
= (2.3/43.7) ´
100 % = 5.26 %.
Определяем
ошибки, соответствующих коэффициентов
вариации (3.12.):
![]() и
и
![]() .
.
Вычисляем
фактическую величину t (3.13.):
![]() .
.